Raw Data (paper uses 1 March 1996-30 September 1997)
A neural network, using input from the Eta model and upper air soundings, has been developed for the probability of precipitation (PoP) and quantitative precipitation forecast (QPF) for the Dallas-Fort Worth, Texas area. Forecasts from 579 days were verified against a network of 36 rain gages. The resulting forecasts were remarkably sharp, with over 70% of the PoP forecasts being less than 5% or greater than 95%. The forecasts of less than 5% PoP were always associated with no rain and the forecasts of greater than 95% PoP were always associated with rain. The linear correlation between the forecast and observed precipitation amount was 0.96. Equitable threat scores for threshold precipitation amounts from 0.05" to 1" are 0.63 or higher, with maximum values over 0.86. Combining the PoP and QPF products indicates that for very high PoPs, the correlation between the QPF and observations is higher than for lower PoPs. In addition, 45 of the 53 observed rains of at least 0.5" are associated with PoPs greater than 85%. As a result, the system indicates a potential for great improvements in thestate of precipitation forecasting.
Forecasts of precipitation are important in a variety of contexts. The probability of precipitation (PoP) is important for many decision makers who are sensitive to the occurrence of precipitation (e.g. Roebber and Bosart 1996). An accurate quantitative precipitation forecast (QPF) can identify the potential for heavy precipitation and possible associated flash flooding, as well as providing information for hydrologic interests. Placement and timing of QPF output can have significant impacts on river forecasts. Accurate QPFs are especially difficult in convective environments. As part of the modernization of the National Weather Service (NWS), more emphasis is being placed on the local generation of QPFs and their subsequent use in hydrological models at River Forecast Centers.
Numerical weather prediction models provide direct QPF guidance for precipitation forecasts. As long as the predictions contain biases and systematic errors, however, post-processing of the output can improve the raw output. Many statistical methods can be used to do this post processing. Traditionally, these have included the "perfect prog" technique (Klein et al. 1959) and Model Output Statistics (MOS) (Glahn and Lowry 1972). Both of these methods use multiple regression techniques to take model output and convert into forecasts of sensible weather. They allow for a single model solution to show uncertainty in the forecast weather. As Murphy (1993) has shown, such an expression of uncertainty can be valuable to forecast users. Recently, hydrometeorologists at the West Gulf River Forecast Center have used another statistical processing technique, neural networks (Müller and Reinhardt 1991), to develop a precipitation forecasting tool for the Dallas-Fort Worth (DFW), Texas metropolitan area. The neural network scheme uses gridded output from the National Centers for Environmental Prediction's (NCEP) Eta model, and upper air soundings from Fort Worth. The forecasts are for the PoP and 24-hour precipitation amount from 1200 UTC to 1200 UTC. Verifying observations are determined by taking the arithmetic mean of 36 rain gages in the DFW area. A precipitation event requires that this areal mean be greater than or equal to 0.01". In this paper, we describe the development of the neural network forecasts and report on the verification of forecasts that have been made from 1 March 1996 to 30 September 1997, a period covering 579 days. There are forecasts and data available from every day in the period.
Neural networks provide a methodology for extracting patterns from noisy data. They have been applied to a wide variety of problems, including cloud classification (Bankert 1994) and tornado warnings (Marzban and Stumpf 1996) in a meteorological context. The advantages and disadvantages of neural networks in comparison to other statistical techniques for pattern extraction are discussed in Marzban and Stumpf (1996).
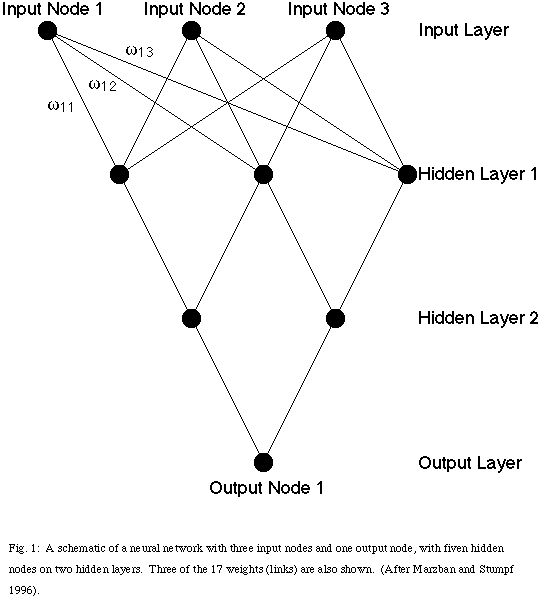
The standard procedure for use of a neural network involves "training" the network with a large sample of representative data. The network has some number of input and output "nodes" representing the predictor and predictand variables, respectively (Fig. 1). In between, there are a number of hidden nodes arranged in layers. The number of hidden nodes and layers is usually determined empirically to optimize performance for the particular situation. Each connection between nodes on a particular layer and the layer above itcan be represented by a weight, wij, that indicates the importance of that connection between the i th and j th nodes. The training phase of the neural network is designed to optimize the weights so that the mean squared error of the output is minimized. The network then can be used to make predictions based on new input values. In our application, we have created two networks: a QPF network for amount of precipitation and a PoP network for probability or confidence in the forecast.
The QPF network was developed to predict 24-hour areal average rainfall, not a point maximum rainfall. We compute 24-hour (1200 UTC to 1200 UTC) mean daily precipitation based on precipitation reports from 36 locations around the Dallas/Fort Worth Metroplex. For the PoP network, "nonrain" days were identified as zeroes and "rain" days as ones. The resulting output of the PoP network was a number between 0 and 1, which could be multiplied by 100 to give a percentage. The networks were trained initially on data from all days from 1994 and 1995, regardless of the amount of precipitation that occurred.
Input data used to train the networks consist of 19 meteorological variables (Table 1), plus the observed rainfall. The input variables come from the Fort Worth, Texas upper air soundings, and from the Eta forecast model. Gridded model data were entered from PC-GRIDDS and text values came from AFOS products (header NMCFRH69). Various "test" networks were developed to determine the quantity, as well as which combination of meteorological variables would provide the best possible "picture" of the available moisture, lift, and instability. Initial developmental networks were smaller, and focused primarily on the key ingredients usually present for heavy to excessive rainfall (Junker 1992; Borneman and Kadin 1993). Additional variables were included later, based on experience from decision tree approaches to QPF (e.g., Johnson and Moser 1992). We eventually ended up with the 19 meteorological variables presently being used.
The networks were designed with three important features. The first was year-round applicability. Networks were developed separately for both the "warm" (April through October) and "cool" (November through March) seasons. The second feature was to expedite the entire process by running both the QPF and POP networks simultaneously, and generate the output on one computer at the same time. Lastly, the networks are interactive; as such, one can change any of the variables desired and "rerun" the networks to accommodate any anticipated meteorological changes. This "interaction" is proving to be a great learning technique for forecasters by allowing them to carry out "what if" exercises. For example, if forecasters believe that the model is not handling moisture return well, they can vary the input value and see what effect that has on the forecast. If the timing of frontal passage is in question, values from another location on the other side of the front can be tested.
Numerous sensitivity analyses have been completed on the networks. The network is retrained and a sensitivity analysis is done every month. These analyses change slightly after each network retraining, but the performance of the network was not significantly different in the two March-September periods after the initial training period. This indicates that little additional skill has been derived after the initial training period. The most important variables are somewhat different for the warm and cool seasonnetworks, but precipitable water is the most important in each case (Table 2).
a. Probability of precipitation (PoP)
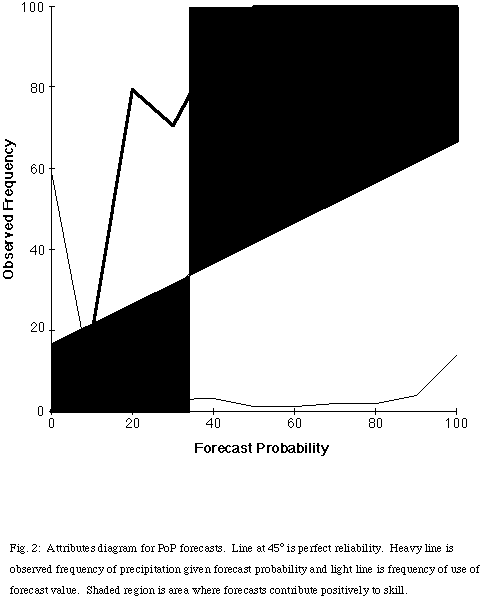
An attributes diagram (Hsu and Murphy 1986) summarizes the performance of the probability of precipitation (PoP) forecasts graphically (Fig. 2). For convenience in presentation, we have combined the forecasts into 11 categories, rounded to the nearest 10%. It did not rain on any of the 342 forecasts in the 0% category and it rained on all 80 forecasts in the 100% category. The PoP was underforecast for all categories from 10% through 90%. In fact, it rained on all forecasts with a PoP greater than or equal to 38.5%. However, it is important to note the frequencies at which forecasts were issued. The two most common forecast categories were 0% (59.1% of forecasts) and 100% (13.8% of forecasts). Only 12.1% of the forecasts were in the 30% through 80% categories. As a result, the forecasts had the desirable properties of sharpness and resolution (Murphy 1993). Simple recalibration of the forecasts could be done to increase the forecast PoP when the system produces values above approximately 40%.
The sharpness of the forecasts and the perfect performance for the forecasts of 0 and 100% lead to a skillful forecast system, with respect to climatology. The Brier score, BS, (Brier 1950; Wilks 1995) averages the squared differences between forecasts and events:
where fi is the i th forecast , xi is the i th event (xi = 0% for no rain and 100% for rain), and n is the number of forecasts. A skill score, SS, can be computed using the performance of some reference forecast system, SS =1-(BS/BSref), where BSref is the Brier score of the reference system (Wilks 1995). Using the sample climatology (33.9%) of precipitation as the reference system, SS for the neural net forecast is 70.9%.
b. Quantitative precipitation forecasts
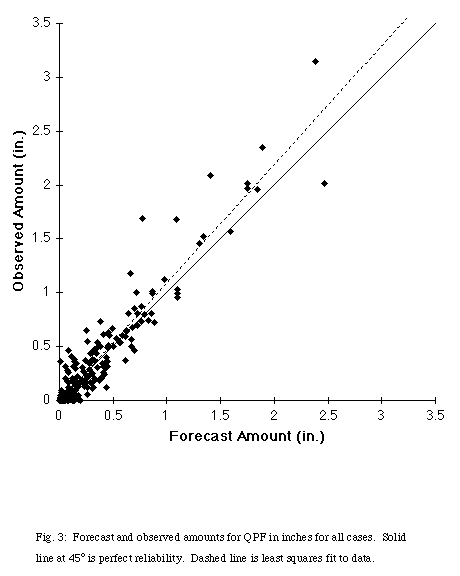
The distribution of forecast and observed precipitation amounts illustrates the accuracy of the forecasts (Fig. 3). The linear correlation coefficient between the forecast and observed amounts is 0.96. Eliminating the 209 forecasts of no precipitation when no precipitation occurred (may of which were, arguably, "easy" forecasts) lowers the coefficient only to 0.95. The least squares linear regression fit of observed to forecast amount is xi =1.10fi - 0.013, where xi and fi are the observed and forecast amounts in inches, respectively. Thus, there is a small conditional bias, with low precipitation amounts being overforecast and high precipitation amountsbeing underforecast.
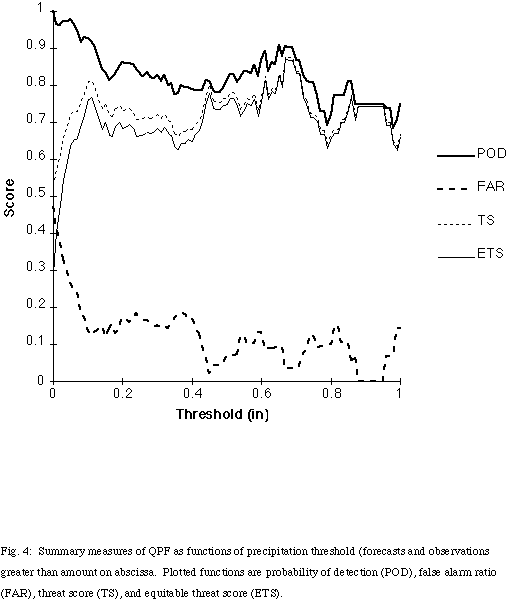
By considering QPF as a forecast of rain greater than a certain threshold, the problem can be broken down into a series of 2x2 contingency tables, each for a different threshold value. Thus, for example, we can consider the performance of the system for forecasts and observations of rain greater than 0.5". Then, standard measures of performance of the system for 2x2 contingency tables can be computed for each threshold (Doswell et al. 1990; Murphy 1996).The probability of detection of rain is above 0.75 for almost all threshold values up to 1" (Fig. 4). At the same time, the false alarm rate is quite low, below 0.20 for all thresholds between 0.08" and 1". As a result, the threat score or critical success index [originally known as Gilbert's ratio of success (Gilbert 1884)] never goes below 0.63 for any threshold between 0.03" and 1" and is above 0.75 for almost all values between 0.44" and 0.73". The equitable threat score (ETS), which is designed to penalize overforecasting events in comparison to the threat score, follows the threat score and is only slightly lower at the low threshold values (minimum value 0.63 between 0.05" and 1"), where some overforecasting exists. These values are quite high, in comparison to operational numerical weather prediction systems, where the ETS rarely exceeds 0.4 (e.g., Rogers et al. 1996).
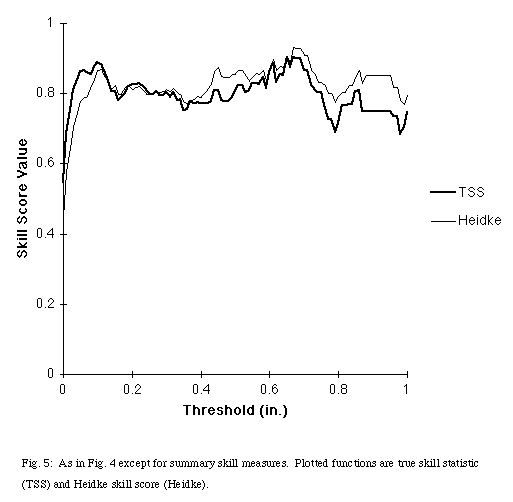
Skill measures, such as the true skill statistic (TSS) [also known as Kuiper's performance index, originally Peirce's "i " (Peirce 1884)] and the Heidke skill score [originally Doolittle's association ratio (Doolittle 1888)] are correspondingly high (Fig. 5). They calculate the performance of a forecasting system relative to how well a system based purely on chance would do. The TSS is greater than 0.68 for all values from 0.05" to 1" and Heidke skill score is above 0.77 for that range. These values indicate that the neural net is performing far better than chance for a wide range of values of precipitation.
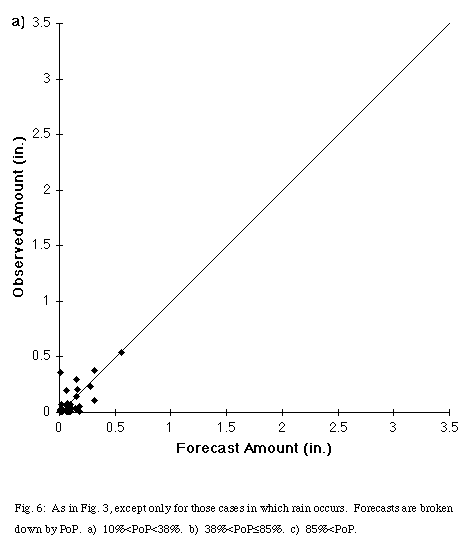
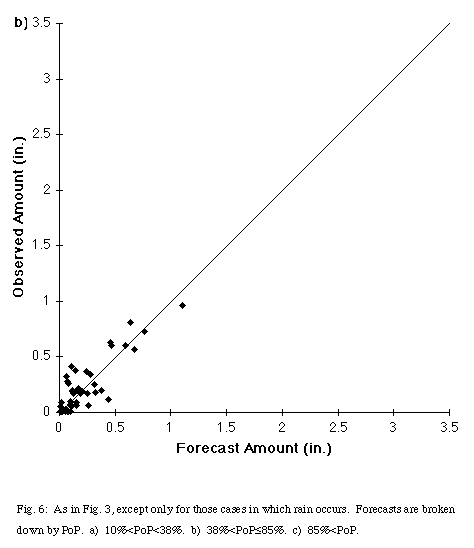
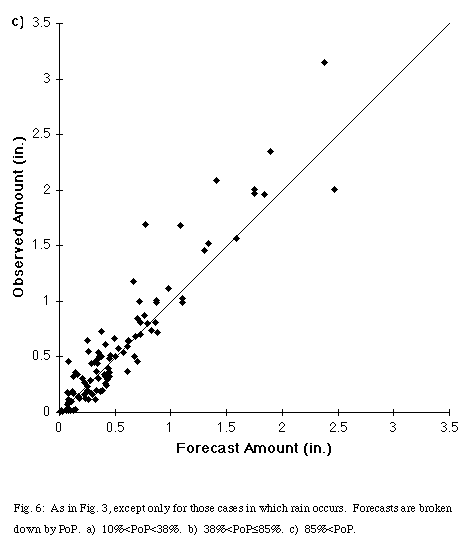
It was noted earlier that rain occurred for all forecasts with a PoP greater than or equal to 38.5%. Recalibration could improve the reliability of the PoP forecasts, but the raw output PoP has value in the QPF problem, that is, the correlation between forecast and observed precipitation amounts increases with the PoP. For the 49 cases where rain occurred with forecast PoPs less than 38%, the correlation was 0.69. The correlation increases to 0.86 for the 45 cases of PoPs between 38.5% and 85%, and reaches 0.94 for the 102 cases with PoPs greater than 85%. Thus, increasing PoPs indicate greater confidence in the forecast amount of precipitation.
Separating out those three classes also illustrates another feature of the system, the tendency to increase PoPs with higher forecast precipitation amount (Fig. 6a, Fig. 6b, Fig. 6c). Forecast or observed precipitation exceeded 0.4" in only one case for the low PoP class and exceeded 0.9" in only one case for the medium PoP class. In the high PoP class, 12 of the 102 cases had both forecast and observed precipitation greater than 1". The network still produces high PoPs for some light rain events. Fourteen of the 102 high PoP cases had QPF values of 0.1" or less. Corresponding with the tendency for high rainfall events to have higher PoPs, the average precipitation increases with increasing PoP (Table 3). The mean value of precipitation for the high PoP case exceeds the maximum value in the low PoP case. As a result, forecasters using this system can calibrate their confidence in both ordinary and extreme rainfall events.
The neural network has produced a remarkably good forecast of both the probability and amount of precipitation for the Dallas-Fort Worth area, far outstripping current precipitation forecasting performance. Clearly, additional work needs to be done to test the network. In particular, the applicability to other locations is an important issue. However, the relative performance of the network could fall off significantly and still be a valuable forecast tool. Such techniques show promise for improving precipitation forecasts dramatically, particularly for hydrologic applications. It is possible that they may be a useful tool for processing model output for other forecast problems as well.
Bankert, R. L., 1994: Cloud classification of a AVHRR imagery in maritime regions using a probabilistic neural network. J. Appl. Meteor., 33, 909-918.
Borneman, R and C. Kadin, 1994: Catalogue of heavy rainfall cases of six inches or more over the continental U.S. NOAA Technical Report NESDIS 80.
Brier, G. W., 1950: Verification of forecasts expressed in terms of probabilities. Mon. Wea. Rev., 78, 1-3.
Brooks, H. E., A. Witt, and M. D. Eilts, 1997: Verification of public weather forecasts available via the media. Bull. Amer. Meteor. Soc., 78, 2167-2177.
Doolittle, M. H., 1888: Association ratios. Bull. Philos. Soc. Washington, 7, 122-127.
Doswell, C. A. III, R. Davies-Jones, and D. L. Keller, 1990: On summary measures of skill in rare event forecasting based on contingency tables. Wea. Forecasting, 5, 576-585.
Gilbert, G. K., 1884: Finley's tornado predictions. Amer. Meteor. J., 1, 166-172.
Gillispie, M., 1993: The use of neural networks for making quantitative precipitation forecasts. NWS Southern Region Technical Attachment, SR/SSD 93-42.
Glahn, H. R., and D. A. Lowry, 1972: The use of Model Output Statistics (MOS) in objective weather forecasting. J. Appl. Meteor., 11, 1203-1211.
Hsu, W.-R., and A. H. Murphy, 1986: The attributes diagram: A geometrical framework for assessing the quality of probability forecasts. Int. J. Forecasting, 2, 285-293.
Johnson, G.A., and J. Moser, 1992: A decision tree for forecasting heavy rains from mid-latitude synoptic patterns in Louisiana generally from late fall through spring. NOAA Technical Memorandum NWS ER-87.
Junker, N. W., 1992: Heavy Rain Forecasting Manual. [Available from National Weather Service Training Center, 617 Hardesty, Kansas City, MO, 64124-3032.]
Klein, W. H., B. M. Lewis, and I. Enger, 1959: Objective predicition of five-day mean temperature during winter. J. Meteor., 16, 672-682.
Marzban, C. And G. J. Stumpf, 1996: A neural network for tornado predictionbased on doppler radar-derived attributes. J. Appl. Meteor., 35, 617-626.
Müller, B., and J. Reinhardt, 1991: Neural Networks: An Introduction. Vol. 2, The Physics of Neural Networks Series, Springer-Verlag, 266 pp.
Murphy, A. H., 1993: What is a "good" forecast? An essay on the nature of goodness in weather forecasting. Wea. Forecasting, 8, 281-293.
_____, 1996: The Finley affair: A signal event in forecast verification. Wea. Forecasting, 11, 3 20.
Peirce, C. S., 1884: The numerical measure of success of predictions. Science, 4, 453-454.
Roebber, P. J., and L. F. Bosart, 1996: The complex relationship between forecast skill and forecast value: A real world analysis. Wea. Forecasting, 11, 544-559.
Rogers, E., T. L. Black, D. G. Deaven, G. J. DiMego, Q. Zhao, M. Baldwin, N. W. Junker, and Y. Lin, 1996: Changes to the operational "early" Eta analysis/forecast system at the National Centers for Environmental Prediction. Wea. Forecasting, 11, 391-413.
a) Warm season
b) Cool season
Table 3: Summary measures of association and central values for QPF by PoP class for cases in which rain occurred. Values except for correlation and number of events (n) in inches.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Fig. 1: A schematic of a neural network with three input nodes and one output node, with fiven hidden nodes on two hidden layers. Three of the 17 weights (links) are also shown. (After Marzban and Stumpf 1996).
Fig. 2: Attributes diagram for PoP forecasts. Line at 45o is perfect reliability. Heavy line is observed frequency of precipitation given forecast probability and light line is frequency of use of forecast value.Shaded region is area where forecasts contribute positively to skill.
Fig. 3: Forecast and observed amounts for QPF in inches for all cases. Solid line at 45 o is perfect reliability. Dashed line is least squares fit todata.
Fig. 4: Summary measures of QPF as functions of precipitation threshold (forecasts and observations greater than amount on abscissa. Plotted functions are probability of detection (POD), false alarm ratio (FAR),threat score (TS), and equitable threat score (ETS).
Fig. 5: As in Fig. 4 except for summary skill measures. Plotted functions are true skill statistic (TSS) and Heidke skill score (Heidke).
Fig. 6: As in Fig. 3, except only for those cases in which rain occurs. Forecasts are broken down by PoP. a) 10% < PoP < 38%, b) 38% < PoP < 85%, c) 85% < PoP.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}